Simulator
Try the Container Gateway Simulator to better understand all of the concepts described here, and how they impact system performance.Settings
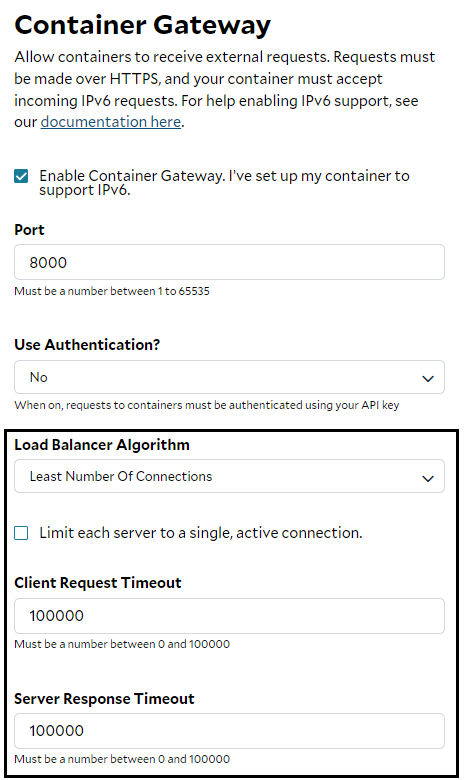
Algorithms
There are two load balancing algorithms currently supported by SaladCloud: Round Robin and Least Number of Connections. Round Robin: This algorithm evenly distributes incoming requests to instances within a container group in a sequential and cyclical order, without considering the instance’s current load or processing power. It is ideal for a container group using the single GPU type, especially when all requests have similar processing time and the workload is light. Least Number of Connections: This algorithm continuously monitors the load on each instance and directs new requests to those with the fewest active connections. By prioritizing the least-loaded instances and preventing any one from becoming overwhelmed, it balances workloads more effectively and optimizes system performance, resulting in greater efficiency and reliability. Processing time for AI inference can vary significantly based on factors like image size, context length, and audio duration. Additionally, deploying a container group with multiple GPU types that share the same VRAM size but have different processing capabilities can further complicate this variability. In most cases, the Least Number of Connections algorithm can effectively manage these differences and is recommended for optimal performance.Concurrency
To enhance overall performance and throughput, the container gateway typically utilizes multiple connections to each instance and sends multiple requests to the instance concurrently. For inference servers, it is ideal to design them to handle multiple simultaneous requests. This includes incorporating a local queue to buffer requests, the ability to accept new requests during inference (non-blocking I/O), explicitly rejecting excessive requests as a back-pressure mechanism when the queue is full, and supporting batched inference by grouping incoming requests or performing single inference. Some inference servers support streaming mode, enabling real-time responses during the inference process rather than waiting for the entire process to complete. This capability is particularly useful for LLMs. In contrast to batched or single inference, using multiprocessing or multithreading for concurrent inference on a single GPU may limit optimal GPU cache utilization and negatively impact performance; therefore, this approach should generally be avoided. To support various inference servers and use cases, two settings are available for concurrency: When the option - “Limit each server to a single, active connection” is unselected, the container gateway will establish multiple connections per instance and forward concurrent requests to the inference server in the container. This server should be capable of handling multiple requests simultaneously, including a local queue, use non-blocking I/O and have a back-pressure mechanism. When the option - “Limit each server to a single, active connection” is selected, the container gateway will use a single active connection per instance and only forward one request at a time to an instance, even when using HTTP/2 multiplexing. New requests will wait and be queued by the container gateway until the current one is processed and a response is returned by the instance. This configuration ensures that an instance receives and processes only one request at any time. Note that a WebSocket connection treated as a single request. For single inference tasks, such as generating an image at a time, choosing this option can significantly simplify the implementation of the inference server by using synchronous calls. Otherwise, this option will reduce system throughput and should be avoided.Client Request Timeout
This setting (millisecond) determines how long a request can be waiting and queued in the container gateway before being sent, after which a timeout error is returned to the client. The default is 100 seconds (or 100000 milliseconds), which is the maximum allowable waiting time for queued requests. When a container gateway is configured to use multiple connections per instance, this setting can be ignored, as all requests are sent to the instance immediately and would be queued by the inference server. However, if a container gateway is configured to use a single active connection per instance, the setting is crucial in influencing the system behavior:- If set too low, the system may struggle to handle burst traffic.
- If set too high, it could result in longer waiting times on the client side.