Introduction
LLM fine-tuning tasks often require long runtimes—ranging from several hours to multiple days—depending on factors such as GPU type, dataset size, and model complexity, etc. SaladCloud operates on a distributed network of interruptible nodes, meaning any node running your tasks may shut down unexpectedly. Despite this, most Salad nodes remain stable for over 10 hours at a time. To fine-tune LLMs effectively on SaladCloud, it’s important to build resilience into your training workflow. We recommend implementing the following strategies:- Start training from a base model.
- Periodically save training progress by uploading checkpoints to cloud storage.
- If interrupted, automatically resume training from the latest checkpoint by downloading it when your instance restarts on a new node.
Single-Replica Container Group vs. Job Queue System
If you’re running long-duration LLM fine-tuning tasks—spanning tens of hours or even multiple days—you can simplify implementation by creating a dedicated single-replica container group (SRCG) for each task on SaladCloud. Pass task-specific configurations to the SRCG via environment variables, including the number of epochs, batch size, checkpoint and logging intervals, and the paths to datasets, checkpoints, and final model stored in cloud storage. Although the task is temporarily paused during node reallocation after interruptions, our testing shows that total downtime accounts for less than 4% of the overall runtime in multi-day runs. On the other hand, if you’re running many training tasks—such as hyperparameter sweeps—a job queue becomes essential. Systems like GCP Pub/Sub, AWS SQS, Salad Kelpie, or custom solutions using Redis or Kafka can distribute jobs (task-specific configurations) across a pool of Salad nodes. If a node fails during job execution, the job queue ensures the job is retried immediately on another available node . You can further implement autoscaling by monitoring the number of available jobs in the queue and dynamically adjusting the number of Salad nodes. This approach ensures that your target number of tasks is completed within a defined timeframe, while also allowing cost control during periods of lower demand. This guide focuses on the SRCG-based approach. A separate guide will cover job queue integration.Handling Interruptions During Training
Let’s take a look at ft-normal.py to see how the Trainer handles interruptions during training. You can use the provided Dockerfile to set up a local virtual environment and run the code. This example code performs supervised fine-tuning of a 4-bit quantized LLaMA 3.1 8B model on a price prediction task using LoRA adapters. Instead of updating all 8 billion base model parameters (approximately 16 GB), it fine-tunes only a small set of adapter weights—about 27.3 million parameters (109.1 MB)—significantly reducing memory and compute requirements. Despite training far fewer parameters, LoRA often matches the performance of full fine-tuning on many tasks. It works by injecting learnable low-rank updates into specific attention layers, effectively capturing task-specific patterns while preserving the base model’s general knowledge. This makes LoRA especially well-suited for efficiently adapting large models to domain-specific tasks. Here are some samples from the training dataset:| No | Samples |
|---|---|
| 1 | How much does this cost to the nearest dollar?\n\nFurrion Access 4G LTE/WiFi Dual Band Portable Router with 1GB of Data Included. Works Omni-Direction Rooftop Antenna to Provide high-Speed Internet connectivity on The go - White\nWORKS WITH FURRION ACCESS ANTENNA Works exclusively with Furrion Omni-directional rooftop antenna to keep you fully connected when you’re on the move. EXTENDED WIFI AND 4G The LTE Wi-Fi Router provides speeds up to (support LTE Band and has a Wi-Fi range extender for improved signal strength. Allows you to connect up to 30 devices and auto-switch between 4G and WiFi. WiFI NETWORK SECURITY Allows you to connect to available 2.4GHz and 5 GHz WiFi signals and gives you peace of mind with WiFi network\n\nPrice is $247.00 |
| 2 | How much does this cost to the nearest dollar?\n\nABBA 36 Gas Cooktop with 5 Sealed Burners - Tempered Glass Surface with SABAF Burners, Natural Gas Stove for Countertop, Home Improvement Essentials, Easy to Clean, 36 x 4.1 x 20.5\ncooktop Gas powered with 4 fast burners and 1 ultra-fast center burner Tempered glass surface with removable grid for easy cleaning Lightweight for easy installation. Installation Manual Included Counter cutout Dimensions 19 3/8 x 34 1/2 (see diagram) Insured shipping for your satisfaction and peace of mind Brand Name ABBA EST. 1956, Weight 30 pounds, Dimensions 20.5\ D x 36\ W x 4.1\ H, Installation Type Count\n\nPrice is $405.00 |
| 3 | How much does this cost to the nearest dollar?\n\nPower Stop Rear Z36 Truck and Tow Brake Kit with Calipers\nThe Power Stop Z36 Truck & Tow Performance brake kit provides the superior stopping power demanded by those who tow boats, haul loads, tackle mountains, lift trucks, and play in the harshest conditions. The brake rotors are drilled to keep temperatures down during extreme braking and slotted to sweep away any debris for constant pad contact. Combined with our Z36 Carbon-Fiber Ceramic performance friction formulation, you can confidently push your rig to the limit and look good doing it with red powder brake calipers. Components are engineered to handle the stress of towing, hauling, mountainous driving, and lifted trucks. Dust-free braking performance. Z36 Carbon-Fiber Ceramic formula provides the extreme braking performance demanded by your truck or 4x\n\nPrice is $507.00 |
Enabling LLM Fine-tuning on SaladCloud
Required Code Changes
With the provided helper.py—a lightweight 400-line module that handles background data synchronization-you only need 4 small code changes, adding just 6 lines to make ft-normal.py fully compatible with SaladCloud. See ft-interruptible.py for a complete reference.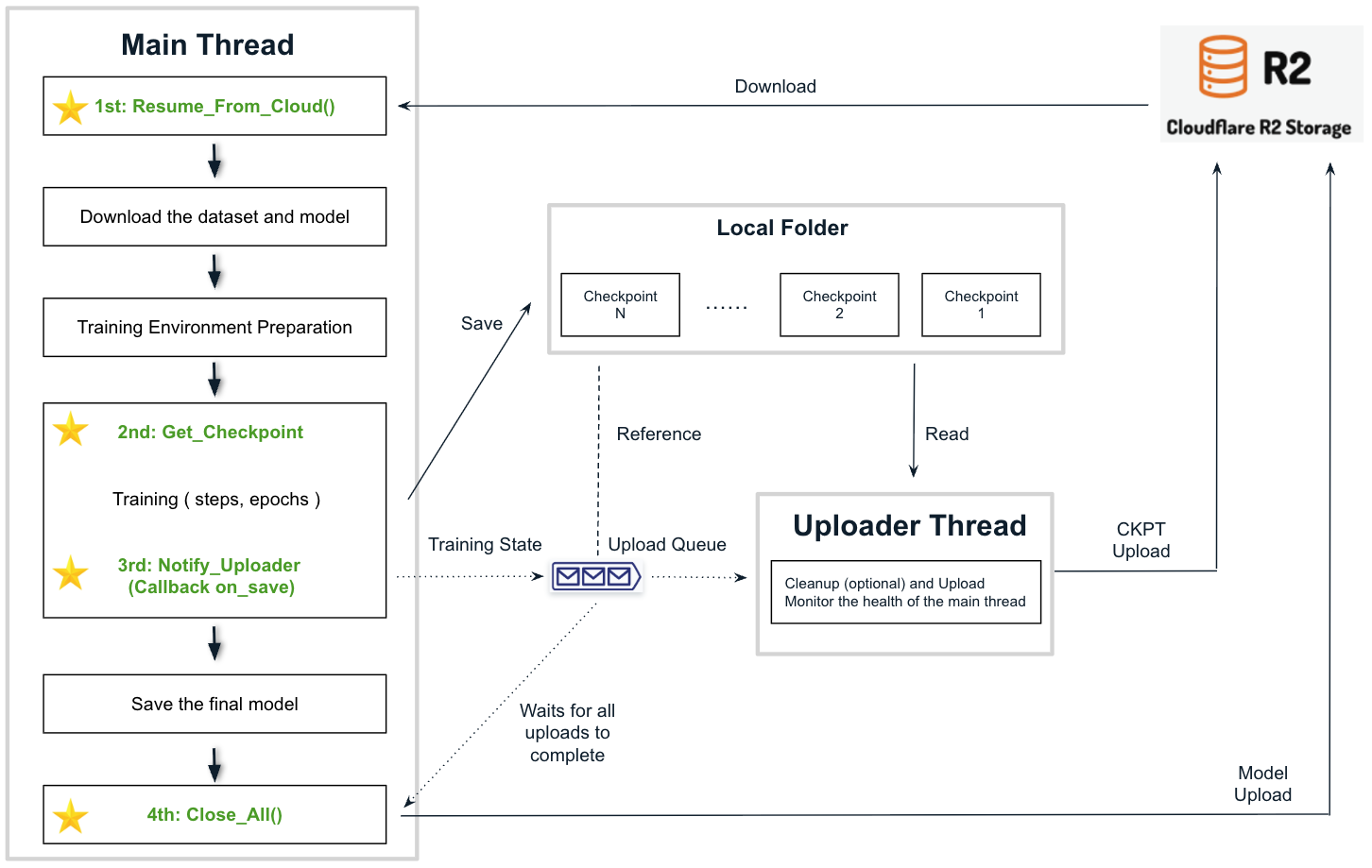
- 1st Change: Import helper and call Resume_From_Cloud()
- 2nd Change: Call the Notify_Uploader() and Get_Checkpoint()
- 3rd Change: Notify_Uploader()
- 4th Change: Call the Close_All() at the end
Dockerfile Configuration
The provided Dockerfile creates a containerized environment by using the PyTorch official image, then installing essential utilities (VS Code Server CLI, Rclone) and required dependencies for training. It copies the required Python code into the image and sets the default command.Dockerfile.ft
Environment Variables
Ensure all required environment variables are set before running a LLM fine-tuning task. You can organize them in a.env file located in the project folder for easy configuration and reuse.
.env
Local Run
If you have an RTX 3090 (24GB VRAM) or a higher GPU, you can perform a local test of the fine-tuning task. To avoid downloading the model and dataset every time the container runs, mount the host cache directory to the container. You can usedocker compose to start the container defined in
docker-compose.yaml. The command
automatically loads environment variables from the .env file in the same directory.
docker run with the required environment variables and volume
mounts.