Limitations
- Our Job Queues are designed to distribute tasks to an HTTP server, and queue operations are managed with http response symantics, e.g. return 200 for a successful job, 500 for a failed job.
- Jobs will be retried up to 3 times (meaning 4 total attempts) before being marked as failed. This limitation in combination with interruptible instances means our job queues are not well suited for extremely long running tasks.
- Instance interruptions count as job failures, and those jobs will be retried according to the above policy.
- Jobs are not guaranteed to be processed in order, but they will be processed in a FIFO manner.
- Jobs are not guaranteed to be processed by the same node, but they will be processed by a healthy node.
- The response body from your http server cannot exceed 10MB.
- Job Queues can only be managed and accessed via the Job Queue API
Terminology
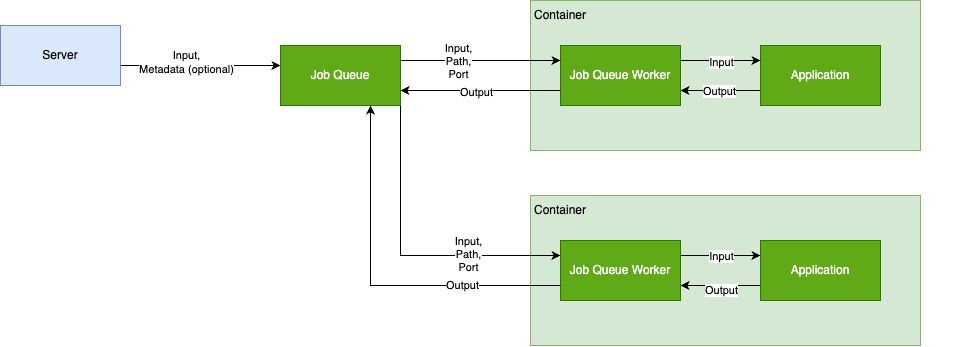
- Job: An individual request to be processed. An example of a job might be a token string sent to an image generation service.
- Job Queue Worker: A small, multi-architecture go binary program you install in your container which receives jobs from the Queue, forwards them to your application running in the container, receives results and returns them to the Queue.
- Job Queue: Salad-managed queue service that receives requests from your systems, queues them, and distributes them FIFO to nodes. Job queues distribute received jobs to one or more container groups. A container group is connected to a Job Queue when the container group is first created.
Architecture
Getting Started with Job Queues
- Create a Job Queue - How-to Guide | API Reference
- Configure the Job Queue Worker - How-to Guide
- Push your container to a registry - Container Registry Guides
- Configure a Container Group with a Job Queue - How-to Guide | API Reference
- Add Jobs to the Queue - API Reference
- Retrieve Results - API Reference | List Jobs