- SaladCloud’s Container Gateway: The client application sends requests to the gateway, which forwards them to the container instances, waits for their responses, and then relays the responses back to the client.
- Job Queue System: Salad Kelpie, Salad Job Queue, AWS SQS, or other queue solutions, such as Redis, RabbitMQ, or Kafka can be used to distribute jobs to instances integrated with a job queue client. The results are then delivered via webhooks or retrieved through job queries.
Container Gateway or Job Queue
SaladCloud’s Container Gateway has a maximum server response timeout of 100 seconds. This timeout specifies the maximum duration the gateway will wait for a response from an instance after forwarding a request. If no response is received within this timeframe, the gateway returns a timeout error to the client. For jobs that may run more than 100 seconds, such as video generation and long audio transcription, you will need to either use webhooks to receive the results asynchronously while still using the gateway, or integrate with a job queue system for better handling of long-running tasks.Concurrency and Throughput
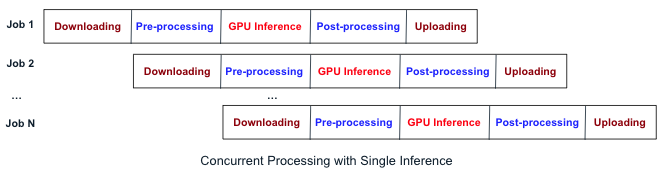
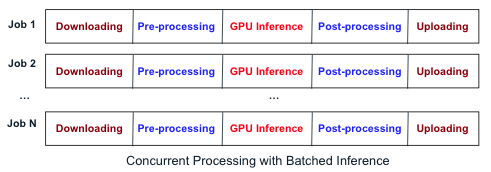
The simplest approach while using the gateway or a job queue is to process a job at a time, ensuring that each job is fully completed before the next one begins.
Save Running State
SaladCloud operates on a foundation of distributed and interruptible nodes, meaning that a node hosting your instance may go down unexpectedly at any time. However, the majority of nodes are capable of running continuously for over 10 hours. Please refer to the benchmark test results detailing uptime and the number of interruptions for jobs running over a 48-hour period on SaladCloud. If an instance fails to complete (or delete) a job due to the node failure, the job will typically become available for other instances via the job queue system. To avoid restarting an unfinished job from scratch after an interruption—particularly for jobs expected to run longer than 30 minutes (depending on the use case), such as molecular dynamics simulations—consider implementing the following features in your applications:- Start fresh while pulling a new job.
- Regularly save and upload the running state to cloud storage during job execution.
- Download and resume from the previous running state if retrieving an unfinished task.
- Longer saving intervals reduce the required upload speed but may result in greater GPU processing losses if nodes go down.
- Shorter saving intervals require higher upload speeds, which may lead to upload backlogs.
- Use Kelpie as a job queue system along with its built-in data synchronization for easy implementation.
- Use Kelpie solely as a job queue while implementing custom, flexible data management strategies, including selective downloads and progressive uploads.
Super Long Running Jobs
Certain large molecular dynamics simulations, or model fine-tunning and hyperparameter tuning jobs, can run for several days or even a week, generating tens to hundreds of gigabytes of data (e.g., trajectory files or checkpoints at various time points) that must be uploaded to cloud storage. This is fully achievable on SaladCloud, as validated by customer use cases. However, both AWS SQS and Salad Job Queue are not ideal for this case. Due to the 12-hour maximum visibility timeout imposed by AWS SQS (starting from when the job is first received, extending the timeout doesn’t reset this limit), the long-running solution built on it can handle tasks for up to 12 hours at a time. After this period, the job reappears in the queue and can be picked up by another instance to continue execution. Salad Job Queue can tolerate up to 3 node failures for a job. When more nodes fail during job execution, the job will be reported as failed. For jobs running longer than a day, the likelihood of failure increases significantly. For super long running jobs, we recommend using Salad Kelpie:- Simplified Architecture: It significantly reduces application complexity by eliminating the need for job and leasing management.
- Enhanced Task Duration: It allows unlimited node reallocations, enabling seamless support for longer running tasks on SaladCloud.
Summary
Here is a summary of the recommended solutions for each scenario:| Job Duration | Use Case | Solution Description |
|---|---|---|
| Under 100 seconds | Image generation, LLM streaming, real-time transcription | SaladCloud’s Container Gateway, or any job queue system. |
| Under 30 minutes | Video generation, LLM non-streaming, long audio transcription | Any job queue system. To handle multiple jobs concurrently while using a job queue, AWS SQS is preferred. |
| Under 12 hours | Molecular dynamics simulation, model fine-tuning | Any job queue system. Applications need to regularly save running state to cloud storage during job execution, and resume from the previous running state if retrieving an unfinished task. Use the Kelpie built-in data synchronization for easy implementation. |
| Over 12 hours | Large molecular dynamics simulation, model fine-tuning and hyperparameter tuning | Salad Kelpie is preferred for simplified architecture and enhanced task duration. For a small number of very long-running jobs, use the single-replica container group, eliminating the need for a job queue. |
| No | Description | Repository |
|---|---|---|
| 1 | Reference implementation of inference server using SaladCloud’s Container Gateway, supporting concurrent processing with batched inference. | link |
| 2 | Reference implementation of inference server integrated with AWS SQS, supporting concurrent processing with single inference. | link |
| 3 | Use Kelpie as the job queue along with its built-in data management. | link |
| 4 | Use Kelpie solely as the job queue, while implementing flexible data management strategies, including selective downloads and progressive uploads | link |
| 5 | Use AWS SQS as the job queue, while implementing flexible data management strategies. | link |