async def, running in the same main thread. By
declaring the predictions function with def, a new thread will be spawned to run the prediction when a new request
arrives.This setup can prevent long-running synchronous predictions from blocking timely responses to health queries.
Another example is IPv6 support: the server is hardcoded to listen on an IPv4 port, we can modify the code to use IPv6
by replacing 0.0.0.0 with :: when launching its underlying Uvicorn server.
The BLIP (Bootstrapping Language-Image Pre-training) supports multiple image-to-text
tasks, such as Image Captioning, Visual Question Answering and Image Text Matching. Each task requires a dedicated and
fine-tuned BLIP model that is 1~2 GB in size. We can run inference for the three models of these three tasks
simultaneously on a SaladCloud node that has a GPU with 8GB VRAM.
LAVIS (A Library for Language-Vision Intelligence) is the Python deep learning
library, and provides the unified access to the pretrained models, datasets and tasks for multimodal applications,
including BLIP, CLIP and others.
Let’s use BLIP as an example to see how to build a publicly-accessible and scalable inference endpoint using the Cog
HTTP prediction server on SaladCloud, capable of handling various image-to-text tasks.
Build the container image
The following 4 files are necessary for building the image, and we also provide some test code in the Github Repo.sed command in the Dockerfile.
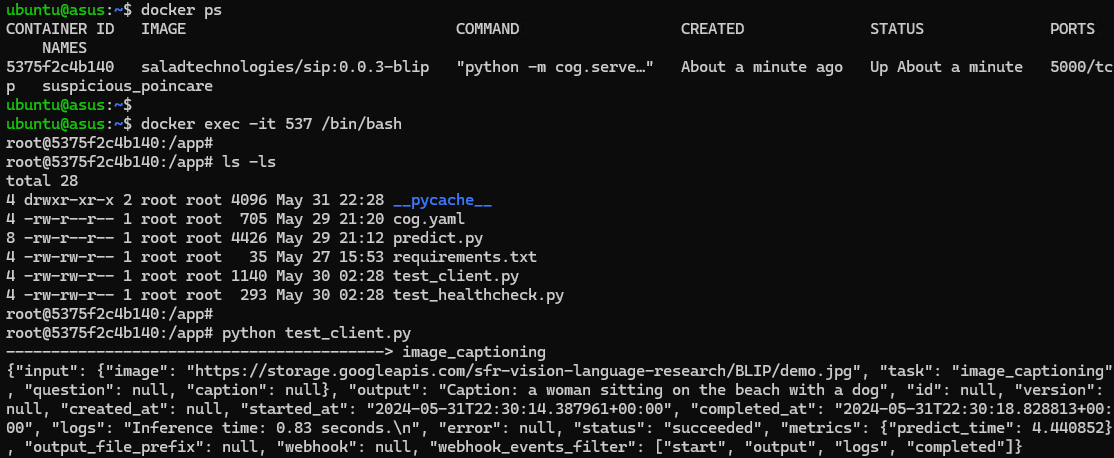
Test the image


Deploy the image on SaladCloud
Create a container group with the following parameters: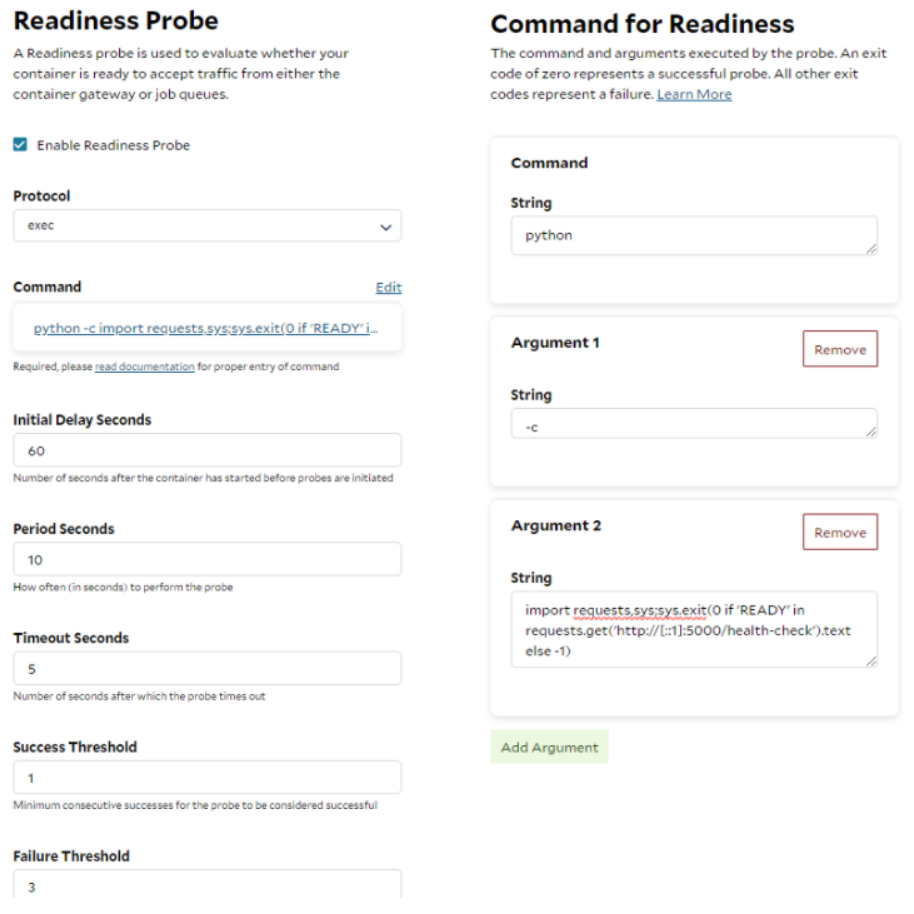
Test the inference endpoint
After the container group is deployed, an access domain name will be created and can be used to access the application.