Real-Time AI Inference with a Redis-Based Queue
Several customers have successfully implemented a Redis-based, flexible and platform-independent queue for real-time applications on SaladCloud, showcasing the following advantages:- The Redis cluster, client applications, and Salad nodes are all strategically deployed within the same region to ensure local access and minimize latency.
- Supports multiple clients and servers, providing real-time request/response functionality in streaming and non-streaming modes with support for synchronous and asynchronous processing.
- More resilient to burst traffic, node failures, and the variability in AI inference times, while allowing easy customization for specific applications, such as using different timeout settings per request and adjusting streaming granularity (tokens or chunks).
- The input and output data of a task can be embedded within the request and response. For large datasets, data exchange can occur directly between client applications or SCE instances and cloud storage, with the request and response containing only a reference to the data.
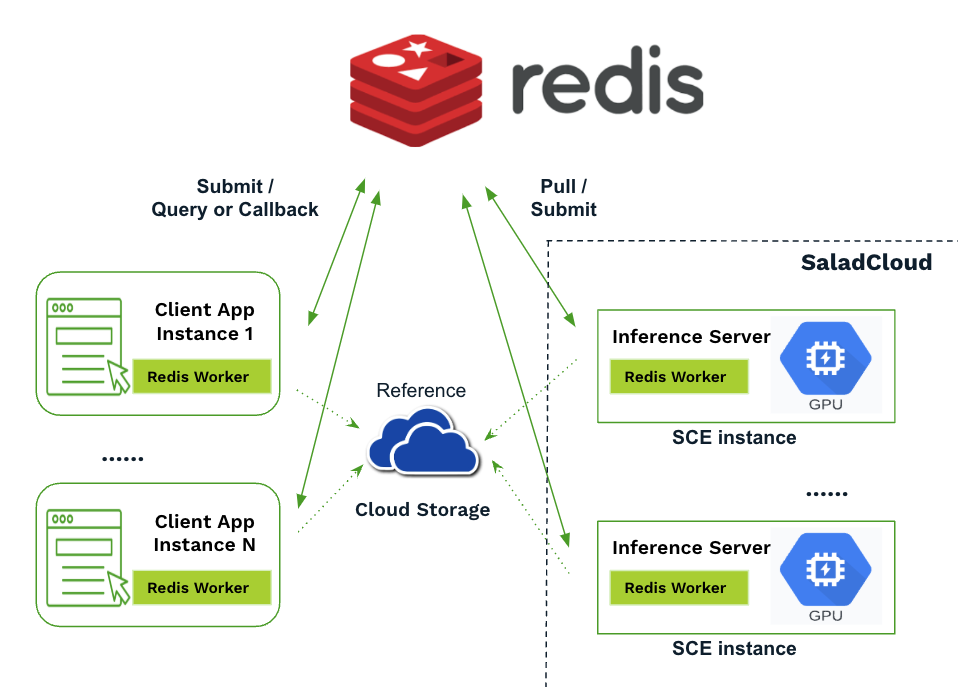
- A self-hosted Redis cluster or a managed service from public cloud providers (considering cost factors).
- Integrate the Redis worker in both client applications and inference servers.
- IP whitelisting for access control is not applicable from Salad nodes to the Redis cluster; instead, application-level authentication can be used.
Key Concepts in Redis
Redis is single-threaded but handles high levels of concurrency efficiently using asynchronous I/O and event-driven architecture, and it supports asynchronous concurrency at the client level. A list in Redis is an ordered collection of elements where items are added in the order they are inserted. It supports efficient insertion and removal of elements from both ends. A list will be automatically removed from Redis once it contains no elements. It also supports blocking operations, such as blocking reads on a non-existent list, with a specified timeout. A zset (sorted set) in Redis is a data structure that contains unique elements, each assigned a score. The elements are stored in order of their scores, allowing efficient retrieval, with the highest-scoring element being accessed and removed first. A hash in Redis is a collection of key-value pairs, where each key is unique and maps to a specific value. It is ideal for representing objects with multiple fields. The Python Redis client uses a connection pool to manage connections efficiently, reducing overhead. Instead of establishing a new connection for each request, it initializes the connection lazily on the first command and reuses it for subsequent requests. The socket_timeout setting defines the maximum time (in seconds) the client will wait for a response from the Redis cluster before timing out. If the cluster does not respond within this duration, the client raises a timeout error. pydantic_redis simplifies working with Redis and Pydantic models together by providing tools for serializing and deserializing Pydantic models, making it easier to manage data between a Redis store and your application.Reference Design: Non-streaming
Please refer to the example code (client, server and common code) in this senario.

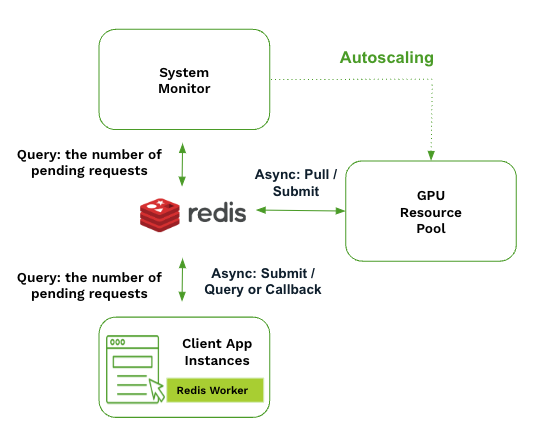
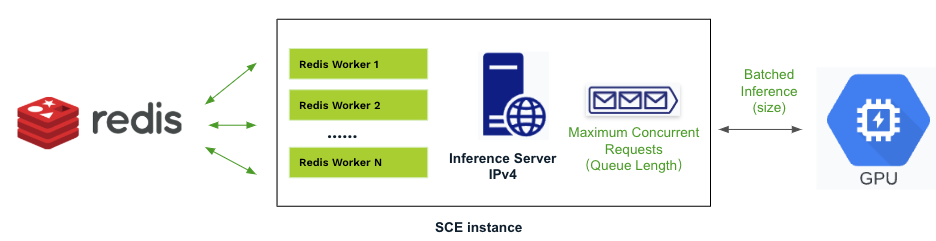
Reference Design: Streaming
Please refer to the example code (client, server and common code) in this senario.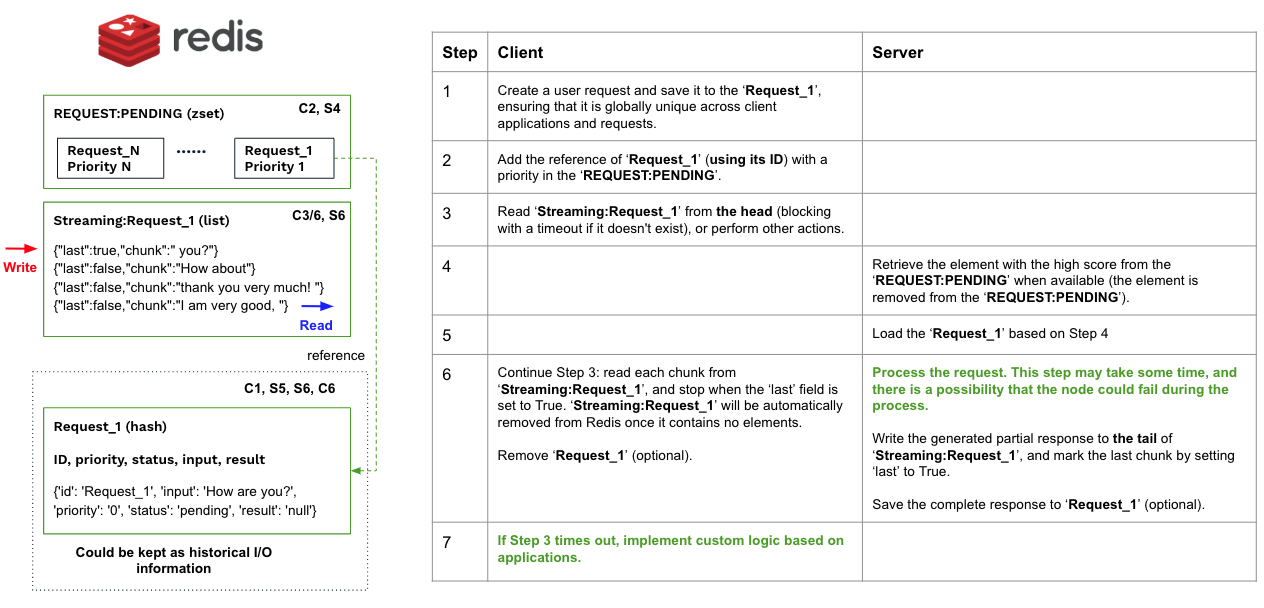
Local Performance Test
From the test, we can see that the real-time queue does not impose an intensive read/write workload on Redis, and its throughput scales linearly with the number of clients and servers. However, a smaller chunk size may reduce transmission efficiency and overall system throughput.