Main Requirements of Real-Time AI Inference
- Typical use cases include image generation, large language models (LLMs), and transcription, where inference times range from a few seconds to minutes, and responses must be delivered in real time to enhance a seamless user experience.
- Unlike traditional web applications, which typically have more consistent response times, AI inference times can be significantly longer and vary widely, even for the same application. For instance, inference times for LLMs are closely tied to the length of generated tokens.
- The ability to return partial responses (such as progress, chunks and tokens) as soon as they are ready, rather than making users wait for the entire response to be generated, can significantly enhance the quality of the user experience.
- As request volumes may fluctuate over time, inference systems should be able to scale efficiently to handle varying demand.
- During system congestion or failures, rejecting new requests early is a better strategy than allowing them to wait for extended periods, only to result in inevitable failures. Fail fast not failure-proof!
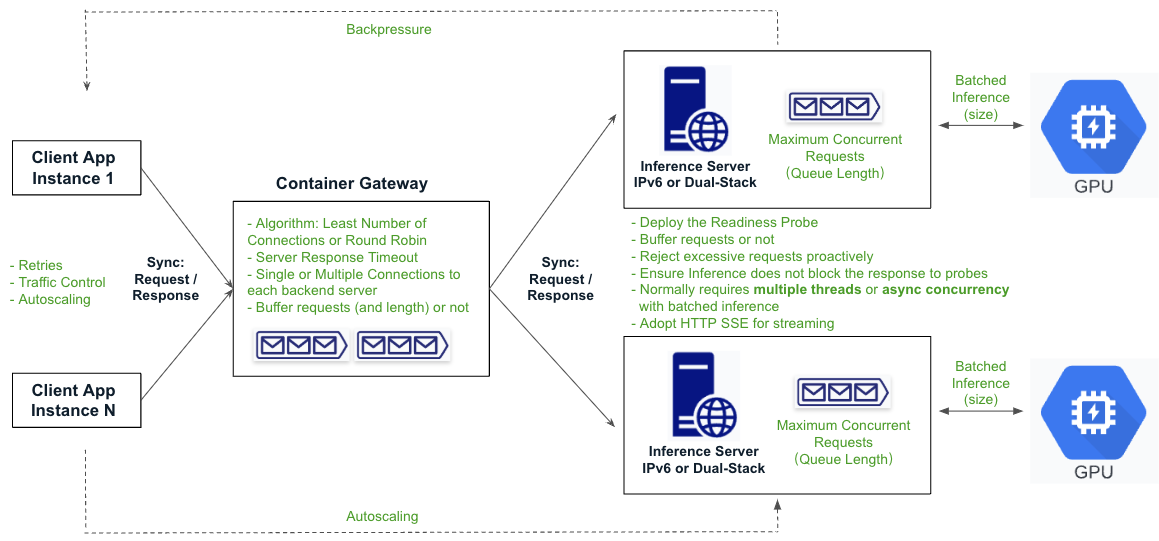
Real-Time AI Inference with SaladCloud’s Container Gateway
Deploying SaladCloud’s Container Gateway is the fastest way to enable input/output to your applications, but additional considerations are required to ensure their success. In the following diagram, all function points highlighted in green must be thoroughly reviewed, correctly configured, and properly implemented.