Solution Overview
Blender render jobs are GPU-intensive workloads that can take anywhere from a few minutes to several days, depending on scene complexity, resolution, number of samples, and total frame count. Each job requires the main .blend file along with associated assets—such as images, audio, and linked .blend files—whose total size can range from hundreds of megabytes up to several gigabytes or more. Some assets may be shared across multiple .blend files. The output, including rendered frames and optionally final video files, is typically much smaller than the input data.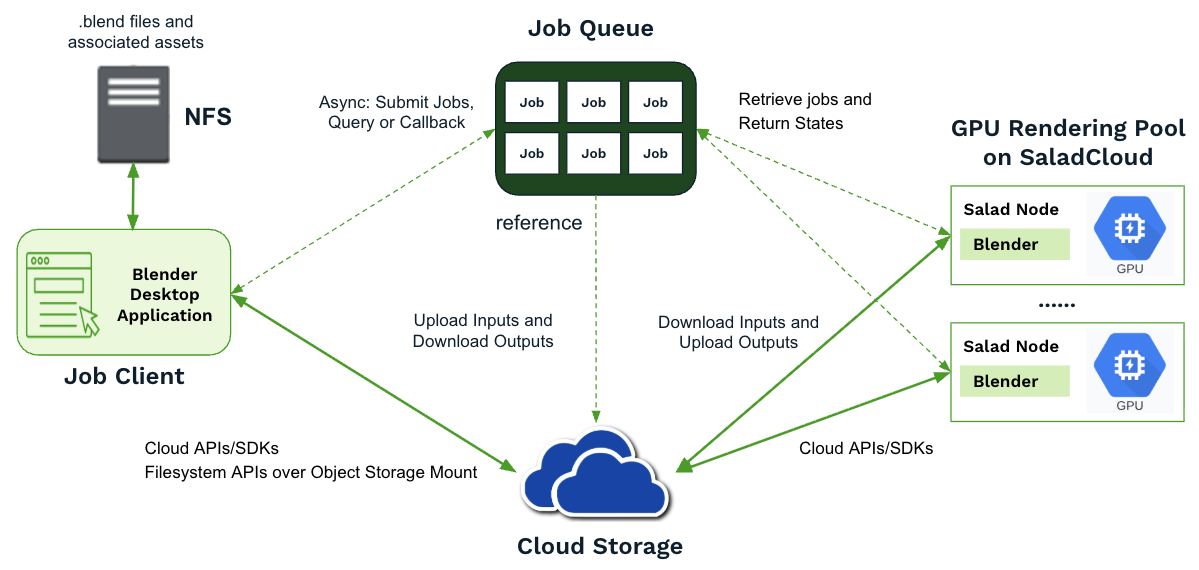
- Chunked execution: Start fresh when pulling a new job, and split a large job into smaller subtasks—for example, rendering a few frames at a time.
- Checkpoint management: Regularly save and upload the job’s progress and intermediate artifacts to cloud storage during execution.
- Resume capability: Download and resume from the previously saved state to continue unfinished tasks after node reallocation.
- Option 1: Make the main .blend file fully self-contained by packing all external resources (File → External Data → Pack Resources in the Blender Desktop Application), converting linked data to local, and baking or converting simulations so that all data is stored within the file. This ensures the .blend file is fully portable and can be processed on any Salad node without missing assets. The main drawback is that shared data may be duplicated across multiple jobs, increasing the total amount of data uploaded to the cloud.
- Option 2: Compress the entire project folder—including all .blend files and assets—into a ZIP file and upload it to cloud storage, where it will be downloaded and processed by Salad nodes. However, very large ZIP files (tens of gigabytes) may reduce efficiency and slow processing on SaladCloud.
- Option 3 (Recommended): The main .blend file contains references to external dependencies. By parsing the main .blend file and any linked .blend files, we can identify all required dependencies and selectively use them to construct a complete job folder to run Blender. This method allows data to be migrated from the local environment to cloud storage without re-packaging or compression. Once stored in the cloud, assets can be shared across multiple jobs, with each Salad node downloading only the files needed for its specific job. The following sections of this guide focus on this approach.
Migrating Data to Cloud Storage
Follow this link to install Rclone on the job client, then use the provided code to configure Rclone with Cloudflare R2. Once configured, you can run Rclone commands to inspect and transfer data between your local system and the cloud.- Dependencies are stored using relative paths.
- The .blend files may link to other .blend files to reuse assets, and multiple .blend files can share the same dependencies; however, no reference files should be located outside the folder containing the main .blend files.