| No | Scenario | Description |
|---|---|---|
| 1 | Both client applications and GPU nodes initiate connections to external job queues, databases and cloud storage. | Client applications submit request jobs to a queue or database, which are then retrieved and processed by the GPU nodes on SaladCloud. Cloud storage can be utilized for data exchange between them. |
| 2 | GPU nodes initiate connections to the Kubernetes clusters. | The GPU nodes on SaladCloud initiate connections to Kubernetes services (or pods), which may include hosted Redis or RabbitMQ instances for job distribution, as well as callback services for receiving results. |
| 3 | Client applications within Kubernetes initiate connections to GPU nodes. | Kubernetes pods initiate connections to GPU nodes on SaladCloud, which typically host inference servers that provide responses based on incoming requests. |
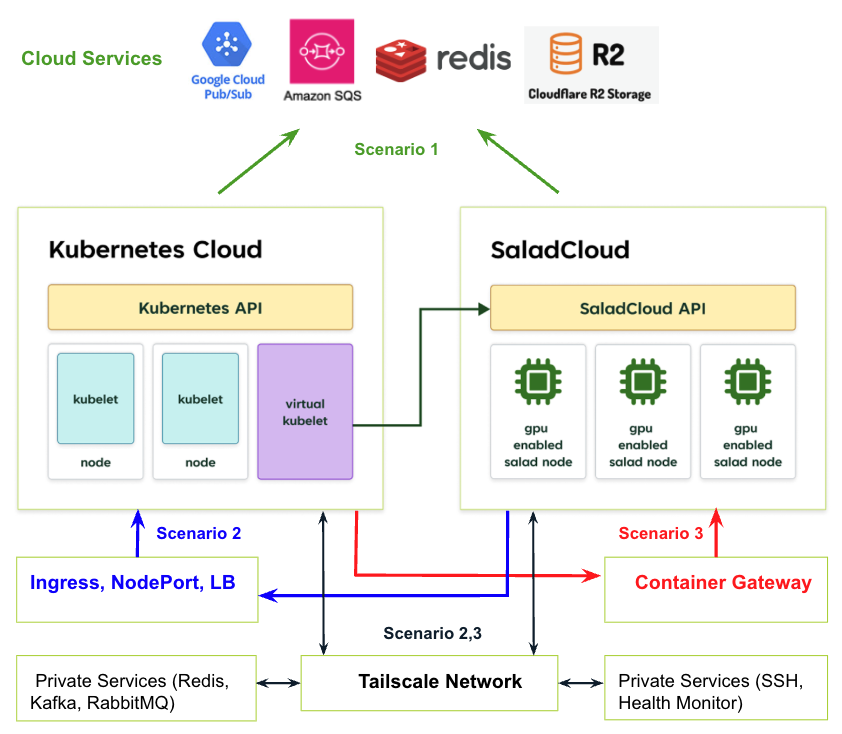
Solution to Scenario 1
This widely adopted scenario decouples client applications and GPU nodes (so they don’t communicate directly), offering enhanced scalability, flexibility, and improved resilience to traffic spikes and node failures. Most existing solutions and applications, including real-time inference, batch processing and long-running tasks, and various types of applications (streaming/non-streaming, synchronous/asynchronous), can be effectively implemented. Supported use cases encompass LLMs, image/video generation, transcription and molecular dynamics simulation, etc. There are multiple options for these external services, such as AWS SQS, GCP Pub/Sub, Salad Kelpie, AWS S3, Cloudflare R2, managed Redis/Kafka/RabbitMQ, and self-managed custom services, among others. Similar to provisioning GPU resources on SaladCloud directly using its APIs/SDKs, you can provide access and credentials to these services by defining environment variables under spec.template.spec.containers in the Kubernetes deployment manifest. These environment variables will then be propagated to SaladCloud GPU nodes while running containers. The Kubernetes-based Event-Driven Autoscaler (KEDA) can be leveraged to implement custom scaling logic, dynamically adjusting GPU nodes on SaladCloud based in response to workload demand through the Kubernetes deployment.Solution to Scenario 2
This scenario applies to a Kubernetes cluster, where GPU nodes on SaladCloud need access to services running within the cluster, either publicly or privately.If Kubernetes clusters are publicly accessible
Kubernetes offers multiple methods to expose a service for external access: One way is to use the NodePort along with a Load Balancer (LB), allowing external access to the service. The exposed service itself can handle authentication using methods such as mTLS (Mutual TLS), JWT (JSON Web Token), API keys, or basic authentication (username/password). You can also deploy a Kubernetes Ingress to centrally manage external access to services within the cluster. The Ingress supports SSL/TLS termination and various authentication methods, reducing the security and authentication burden on individual services. In both approaches, you can pass the necessary access credentials to SaladCloud via the Kubernetes deployment. However, the process can be simplified by using the JWT-based authentication.- Your applications running on SaladCloud GPU nodes can obtain a JWT by querying the local SaladCloud Instance Metadata Service (IMDS), and use it to access the Kubernetes services.
- Within the Kubernetes cluster, the Ingress (or individual services) can be configured to validate the JWT using the public key.
For private Kubernetes clusters
Tailscale enables secure connectivity by establishing direct peer-to-peer connections between machines, even when they are behind firewalls or NAT. It uses WireGuard under the hood, which is a lightweight, fast VPN protocol, to create encrypted tunnels between peers. Tailscale is not a traditional VPN service that routes all traffic through a central server or gateway. Instead, it functions as a network orchestrator, establishing direct, encrypted connections between peers whenever possible. This peer-to-peer design enhances efficiency and significantly reduces costs. We can implement the Tailscale Userspace Networking solution for containers on SaladCloud GPU nodes, as they are not run in privileged mode. This solution utilizes a proxy, enabling local applications on a node to access other nodes via their Tailscale IPs, while also allowing other nodes to reach the node using its Tailscale IP. However, one limitation is that applications on each node cannot access themselves using their own Tailscale IP. This is typically not an issue for most use cases. There are several ways to integrate Tailscale with a private Kubernetes cluster, including using a sidecar and subnet router. These methods enable SaladCloud GPU nodes to access pods in the private cluster, as well as other private services (such as self-managed RabbitMQ and Redis instances) within the same Tailscale network. You need to build the container image with Tailscale support and provide the Tailscale authentication key via the Kubernetes deployment, to join the GPU nodes to the specific Tailscale network. We will soon release a guide for deploying Tailscale with SaladCloud.Solution to Scenario 3
In this scenario, client applications within the Kubernetes cluster make straightforward calls to the inference service hosted on the GPU nodes in SaladCloud, either through public or private access. You may still use the Tailscale-based solution as it offers bidirectional network connectivity, but the solution requires some additional effort and doesn’t work out of the box:- When a GPU node is online, it reports its Tailscale IP to the applications.
- The applications maintain a heartbeat to each GPU node to monitor its health.
- Client-side load balancing is used to distribute traffic efficiently.
- Scalable Inference Architecture: Servers should support multi-threading or asynchronous processing with batched inference to handle varying workloads efficiently.
- Back-Pressure Management: Inference servers can proactively reject excessive requests to prevent overload.
- Client-Side Traffic Control: Applications can implement traffic management strategies to pause new user requests during high congestion.